3 Life tables and single decrement processes
Learning objectives
- Explain what a single decrement process is
- Learn how to summarize a cohort’s experience of a single decrement process using a life table
- Describe the purpose of a period life table and how it differs from a cohort life table
- Know how to construct a period life table under varying assumptions about how to convert period age-specific rates into probabilities
- Interpret the columns of a life table and functions of those columns
- Relate age-specific mortality rates to the force of mortality, and its implications for a common assumption made during life table construction
- Decompose a difference in two life expectancies into age-specific components
- Know the conditions for and definition of a stationary population, and how to use a life table to find relations among its key metrics
Cohort life tables with lifeline data
KEY CONCEPTS
A life table is one of the most important demographic tools for summarizing the mortality experience of a cohort. Also known as a decrement table.
A single decrement process is one where “individuals have only one mode of exit from a defined state” (PHG pg. 65).
A single decrement life table is a tabular summary of a single decrement process.
Since a life table summarizes the experience of a cohort, let’s start by building a life table from the lifelines of a small hypothetical cohort based actual people born January 1, 180024.
Below, a lifelines plot like we drew in week 1, except time is measured from age \(x = 0\), and everybody in this real birth cohort was born January 1, 180025:
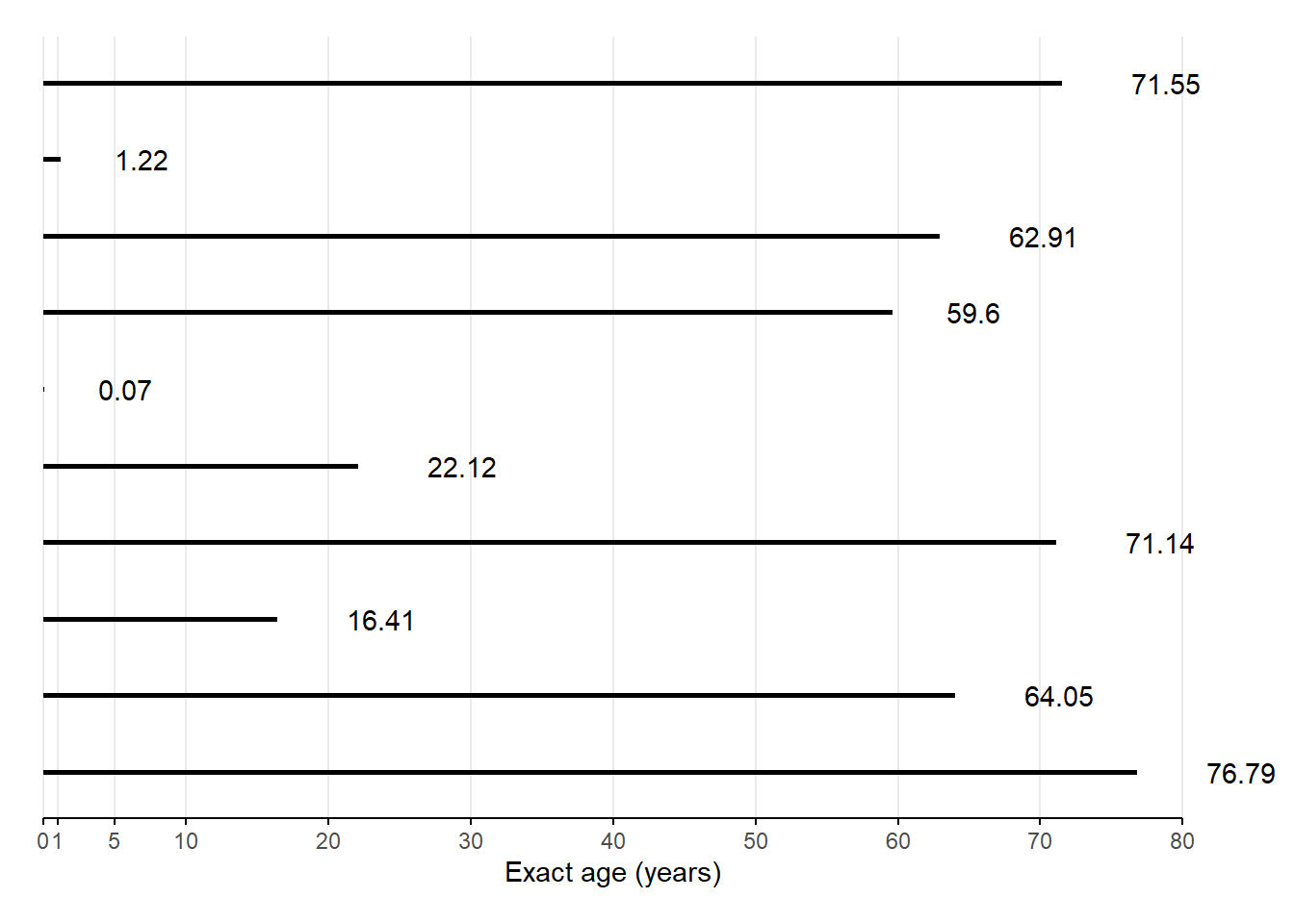
Number \(l_0\) of live births (i.e., number surviving to exact age \(x = 0\))? Tap for answer
$l_{0} = $Number of deaths \({}_{n}d_{x}\) between ages \(x = 0\) and \(x+n = 1\)? Tap for answer
${}{1}d{0} = $Number \(l_x\) still alive at exact age \(x = 1\)? Tap for answer
$l_{1} = l_0 - {}{1}d{0} = $
So in general:
\[l_{x+n} = l_x - {}_{n}d_{x}\]Probability of death \({}_{n}q_{x}\) between ages \(x = 0\) and \(x+n = 1\)? Tap for answer
\[ {}_{1}q_{0} = \frac{{}_{1}d_{0}}{l_0} = \]
So in general:
\[{}_{n}q_{x} = \frac{{}_{n}d_{x}}{l_x}\]Probability of survival \({}_{n}p_{x}\) between ages \(x = 0\) and \(x+n = 1\)? Tap for answer
\[ {}_{1}p_{0} = l_1 / l_0 = 1 - {}_{1}q_{0} = \]
For general \(x\):
\[{}_{n}p_{x} = l_{x+n} / l_x = 1 - {}_{n}q_{x}\]Number of person-years \({}_{n}A_x\) lived by those who died between ages \(x\) and \(x+n\)? Tap for answer
For general \(x\):
\[ {}_{n}A_x = \sum_{i \in \textsf{dead}_x} \left(\textsf{(Exact age at death)}_i - x\right) \]
But for these \(x = 0\) (i.e., infants):
\[\begin{align} {}_{1}A_0 &= \sum_{i \in \textsf{dead}_0} \left(\textsf{(Exact age at death)}_i - 0\right) \\ &= \sum_{i \in \textsf{dead}_0} \textsf{(Exact age at death)}_i \\ &= \end{align}\]
What is the average number of person-years lived \({}_{n}a_x\) by those who died between ages \(x\) and \(x+n\)?
Hint: It’s the average of a similar figure we’ve seen already, thus a ratio of that sum to a count we’ve seen already. Tap for answer
For general age group starting at exact age \(x\):
\[{}_{n}a_x = \frac{{}_{n}A_x}{{}_{n}d_x}\]
But for these \(x = 0\) (i.e., infants):
$$ {}_{1}a_0 = = = $$Person-years lived \({}_{n}L_{x}\) between ages \(x = 0\) and \(x+n = 1\)? Tap for answer
\[\begin{align} {}_{n}L_{x} &= \begin{pmatrix} \textsf{Person-years lived} \\ \textsf{between ages } x \textsf{ and } x+n \\ \textsf{among survivors to age } x+n \end{pmatrix} \times \begin{pmatrix} \textsf{Width of } [x,x+n)\\ \textsf{age interval} \end{pmatrix} \\ &+ \begin{pmatrix} \textsf{Person-years lived} \\ \textsf{between ages } x \textsf{ and } x+n \\ \textsf{among those who died} \\ \textsf{before age } x+n \end{pmatrix} \\ &= \begin{pmatrix} \textsf{Survivor count} \\ \textsf{weighted by} \\ \textsf{interval width} \\ \end{pmatrix} + \begin{pmatrix} \textsf{Fractional person-years} \\ \textsf{lived by the now deceased} \end{pmatrix} \\ &= \left(l_{x+n} \times n\right) + {_n}_{}A_x \end{align}\]
This should look familiar to our expression of person-years from week 1: \(PY[0,1] = \sum_1^P N_i \times \Delta_i\)
So for these 1800 birth cohort infants:
\[\begin{align} {}_{1}L_0 &= l_1 \times 1 + {}_{1}A_0 - 0 \\ &= l_1 + {}_{1}A_0 \\ &= + \\ &= \end{align}\]
Recall that \({}_{n}a_x = \frac{{}_{n}A_x}{{}_{n}d_x}\)
Thus \({}_{n}A_x = {}_{n}a_x \times {}_{n}d_x\)
Thus \({}_{n}L_x = l_{x+n} \times n + {_n}_{}a_x \times {}_{n}d_x\)
This becomes useful when doing period life tables because:
- You can’t calculate \({}_{n}A_x\) directly
- So you can’t calculate \({}_{n}L_x\) from \({}_{n}A_x\) directly
- So you borrow values from a model or another population
- But you want \({}_{n}A_x\) estimates that aren’t contaminated by another population’s size
Person-years \(T_x\) lived above exact age \(x = 0\)? Tap for answer
\[\begin{align} T_0 &= \textsf{Total person years lived from birth to death} \\ &= \sum_i \textsf{(Exact age at death)}_i \\ &= \sum_{a=0}^\infty {}_{n}L_a \end{align}\]
Okay that was too easy, what about \(T_{20}\)? Let’s do it with R code. Tap for answer
More generally:
\[T_x = \sum_{a=x}^\infty {}_{n}L_a\]
Easy to think about, but funky to do in practice.
Let’s walk through how you’d do it with R code.
Say you have a cohort life table in a data.frame with two columns:
-
x: Exact age \(x\) at the beginning of each age interval -
Lx: Person-years \({}_{n}L_x\) lived in the age interval
It looks like this:
| x | Lx |
|---|---|
| 0 | 9.07 |
| 1 | 32.22 |
| 5 | 40.00 |
| 10 | 76.41 |
| 20 | 62.12 |
| 30 | 60.00 |
| 40 | 60.00 |
| 50 | 59.60 |
| 60 | 36.96 |
| 70 | 9.48 |
| 80 | 0.00 |
To create a column T storing \(T_x\) values, do this (assuming you have dplyr installed and loaded):
saving_you_some_time <- cohort_lt_xL %>%
dplyr::mutate(
Lx = dplyr::coalesce(Lx, 0),
Tx = rev(Lx) %>% # Reverse person-years column so sum back to x = 0
dplyr::coalesce(0) %>% # Replace the missing value at x = 80 so you can...
cumsum() %>% # ... take the cumulative sum of person years
rev() # Reverse the cumulative sum back in age order
)
saving_you_some_time %>%
knitr::kable() %>%
kableExtra::kable_paper("hover", full_width = FALSE, position = "left")| x | Lx | Tx |
|---|---|---|
| 0 | 9.07 | 445.86 |
| 1 | 32.22 | 436.79 |
| 5 | 40.00 | 404.57 |
| 10 | 76.41 | 364.57 |
| 20 | 62.12 | 288.16 |
| 30 | 60.00 | 226.04 |
| 40 | 60.00 | 166.04 |
| 50 | 59.60 | 106.04 |
| 60 | 36.96 | 46.44 |
| 70 | 9.48 | 9.48 |
| 80 | 0.00 | 0.00 |
- \({}_{\infty}L_x = T_x = 0\) for the final age group in this case because we know everyone in the cohort died before age 80
- You won’t know that for a period lifetable!
- But notice how \({}_{10}L_{70} = T_{70}\), since everybody dies before age 80
What is the life expectancy at birth, i.e., life expectancy \(e_x^o\) at age \(x = 0\)?
Hint: It’s the per-survivor average of a value we’ve already calculated, so it’s a ratio of that value and another one we’ve already calculated. Tap for answer
\[\begin{align} e_0^o &= \frac{ \textsf{Person-years lived after age } x=0 \textsf{ (i.e., total person-years)} }{ \textsf{People alive after age } x=0 \textsf{ (i.e., live births)} } \\ &= T_0/l_0 = / = 44.586 \end{align}\]
So for general exact age \(x\):
\[e_x^o = T_x/l_x\]
This is the expected years of life remaining after age \(x\)! Not the expected age at death.
To get expected age at death at exact age \(x\):
\[\textsf{Expected age at death at exact age } x = x + e_x^o\]
What is the mortality rate \({}_{n}m_x\) in the cohort between ages \(x\) and \(x+n\) Tap for answer
- This is just a cohort age-specific rate
- Using life table notation, it is:
\[ {}_{n}m_x = {}_{n}d_x / {}_{n}L_x \]
For example, for newborns, we have \({}_{1}m_0\) = 1/9.07 \(\approx\) 0.11QUESTION: Why did we just learn all of those values?
ANSWER: Three reasons:
- I’m evil
- Their relationships and values help create period life tables
- Their values (and operations on them) are interesting in and of themselves
- We’ll see examples of those last two points in later sections.
- You’ve already seen ample evidence of the first point.
Now let’s put all these values together into our first cohort life table:
| \(x\) | \(n\) | \(x+n\) | \(l_x\) | \({}_{n}d_x\) | \({}_{n}q_x\) | \({}_{n}p_x\) | \(L_x\) | \(T_x\) | \(e_x^o\) | \({}_{n}m_x\) | \({}_{n}a_x\) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 10 | 1 | 0.10 | 0.90 | 9.07 | 445.86 | 44.59 | 0.11 | 0.07 |
| 1 | 4 | 5 | 9 | 1 | 0.11 | 0.89 | 32.22 | 436.79 | 48.53 | 0.03 | 0.22 |
| 5 | 5 | 10 | 8 | 0 | 0.00 | 1.00 | 40.00 | 404.57 | 50.57 | 0.00 | |
| 10 | 10 | 20 | 8 | 1 | 0.12 | 0.88 | 76.41 | 364.57 | 45.57 | 0.01 | 6.41 |
| 20 | 10 | 30 | 7 | 1 | 0.14 | 0.86 | 62.12 | 288.16 | 41.17 | 0.02 | 2.12 |
| 30 | 10 | 40 | 6 | 0 | 0.00 | 1.00 | 60.00 | 226.04 | 37.67 | 0.00 | |
| 40 | 10 | 50 | 6 | 0 | 0.00 | 1.00 | 60.00 | 166.04 | 27.67 | 0.00 | |
| 50 | 10 | 60 | 6 | 1 | 0.17 | 0.83 | 59.60 | 106.04 | 17.67 | 0.02 | 9.60 |
| 60 | 10 | 70 | 5 | 2 | 0.40 | 0.60 | 36.96 | 46.44 | 9.29 | 0.05 | 3.48 |
| 70 | 10 | 80 | 3 | 3 | 1.00 | 0.00 | 9.48 | 9.48 | 3.16 | 0.32 | 3.16 |
| 80 | 0 | 0 | 0.00 | 0.00 |
3.1 Period life tables
KEY CONCEPTS
A period life table shows what would happen to a cohort if it were subjected for all of its life to the mortality conditions of that period.
– PHG pg. 42 (bolding added)
| Cohort life table | Period life table |
|---|---|
| Actual cohort | Synthetic (aka hypothetical) cohort |
| Records cohort’s real experience | Model of what would happen |
Why create a period life table, even if you have cohort data? Tap for answer
- Cohort data is unavailable:
- Example: By law, full individual-level U.S. Census records only available starting 72 years ago, reducing sample size for many sub-populations
- Cohort data is outdated:
- Example: \({}_{1}q_{80}\) constructed this year requires data from people born 1942
- Cohort data is incomplete or erroneous:
- Example: Employee termination records for large front line workforce tend to be missing or incorrectly logged
Which of the values we’ve covered so far would be hard to come by in classic demographic data. Why? Tap for answer
- Total or average person-years lived in age intervals (don’t have exact person years)
- Probabilities of death or survival (don’t have cohort data or separated count data)
- Person-years lived in age interval (but could estimate from \(l_x\) and \(l_{x+n}\) using week 2 approximations)
The central importance of \({}_{n}q_x\) and \({}_{n}a_x\)
Once you know \({}_{n}q_x\), you can calculate the rest of life table unknowns.
Recall that:
- \({}_{n}q_x = {}_{n}d_x / l_x\) (unavailable in period data)
- \({}_{n}L_x = n \cdot l_{x+n} + {}_{n}a_x \cdot {}_{n}d_x\) (we don’t have to estimate person-years using approximations if we have \({}_{n}a_x\) estimates)
- \({}_{n}m_x = {}_{n}d_x / {}_{n}L_x\) (we don’t have cohort age-specific rates, but can for now assume they’re equal to period age-specific rates \({}_{n}M_x\)26)
PHG pg. 43 exploits these equations to derive \({}_{n}q_x\) from two life table columns \(\color{dodgerblue}{\textsf{available in period data}}\) and one unknown parameter \(\color{darkorange}{\textsf{unavailable in period data}}\):
\[\begin{equation} \color{darkorange}{{}_{n}q_x} = \frac{ \color{dodgerblue}{n} \cdot \color{dodgerblue}{{}_{n}{m_x}} }{ 1 + \left( \color{dodgerblue}{n} - \color{darkorange}{{}_{n}a_x} \right)\color{dodgerblue}{{}_{n}{m_x}} } \tag{3.1} \end{equation}\]
If we can estimate \({}_{n}a_x\), we can estimate \({}_{n}q_x\) and the rest of the period life table
So we need some…
3.2 Strategies for \({}_{n}m_x\) \(\rightarrow\) \({}_{n}q_x\) conversion
3.2.1 Direct observation
- You can use exact ages at death to estimate \({}_{n}a_x\)
- Yet the values are distorted by within-interval age distribution
- So usually this is a bad idea
3.2.2 Graduation of the age-specific mortality rate (\({}_{n}m_x\)) function
If you know how \({}_{n}m_x\) is changing within an age interval, you can estimate the distribution of deaths within the interval.
Problem: Usually no observations within an age interval
Solution: Can get clues about within-interval changes from the changes in \({}_{n}m_x\) across age intervals
Two example graduation models
\[ {}_{n}q_x = \frac{ {}_{n}m_x }{ 1/n + \left[{}_{n}m_x\left(1/2 + n/12\right)\right]\left( {}_{n}m_x - 19/20 \right) } \]
- Keyfitz29 fits a 2nd degree polynomial to deaths:
\[ {}_{n}a_x = \frac{ -\frac{n}{24} {}_{n}d_{x-n} + \frac{n}{2} {}_{n}d_{x} + \frac{n}{24} {}_{n}d_{x+n} }{ {}_{n}d_x } \]
The polynomial method’s quirks:
Can’t estimate \({}_{n}a_x\) for first or last interval. Why? Tap for answer
Because you need death counts from both previous and next age group.
This limitation is okay since we will use different methods to estimate \({}_{n}a_x\) and \({}_{n}q_x\) for The very young ages and The open-ended age interval anyway.Requires same interval length \(n\) for all age groups. Why? Tap for answer
Look at the first and last elements in the numeratorRequires that you already have estimates of \({}_{n}d_x\)… which you need \({}_{n}a_x\) to estimate in the first place. How to get around this problem? Tap for answer
- Start by Using rules of thumb to estimate \({}_{n}a_x\), which we’ll cover in the next section
- Use those estimates to get to initial \({}_{n}d_x\)
- Plug those initial estimates into Keyfitz’s polynomial to get initial \({}_{n}a_x\)
- Use step 3 estimates to approximate \({}_{n}d_x\) again
- Use step 4 to estimate a new \({}_{n}a_x\)
- Repeat steps 4 and 5 until \({}_{n}a_x\) estimates stabilizes (usually two or three times)
In practice, graudation methods are available in well-tested software packages. Let’s demonstrate one additional graduation method30 using the R package demogR. From the documentation of the demogR::life.table function:
For type=“kf,” the default, the first two values of nax estimated using Keyfitz and Fleiger’s (1990) regression method. For type=“cd,” Coale and Demeny’s method (1983) is used. The Coale-Demeny method uses different coefficients depending on the level of early mortality. As a result, this method may work better for high-mortality populations.
We’ll build a life table for Venezuela 1965 the demogR package’s goodman data set31.
data(goodman)
vlt <- with(goodman, life.table(x = age, nKx = ven.nKx, nDx = ven.nDx))
vlt %>%
knitr::kable() %>%
kableExtra::kable_paper("hover", full_width = FALSE, position = "left") %>%
kableExtra::column_spec(2:9, border_left = TRUE)| x | nax | nMx | nqx | lx | ndx | nLx | Tx | ex |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.1483 | 0.0461 | 0.0443 | 1.0000 | 0.0443 | 0.9622 | 67.70 | 67.70 |
| 1 | 1.5000 | 0.0057 | 0.0226 | 0.9557 | 0.0216 | 3.7687 | 66.74 | 69.84 |
| 5 | 2.5000 | 0.0012 | 0.0058 | 0.9341 | 0.0055 | 4.6568 | 62.97 | 67.41 |
| 10 | 2.5000 | 0.0007 | 0.0036 | 0.9286 | 0.0034 | 4.6347 | 58.31 | 62.80 |
| 15 | 2.5000 | 0.0011 | 0.0054 | 0.9253 | 0.0050 | 4.6138 | 53.68 | 58.01 |
| 20 | 2.5000 | 0.0013 | 0.0065 | 0.9202 | 0.0060 | 4.5863 | 49.07 | 53.32 |
| 25 | 2.5000 | 0.0017 | 0.0086 | 0.9143 | 0.0079 | 4.5516 | 44.48 | 48.65 |
| 30 | 2.5000 | 0.0022 | 0.0109 | 0.9064 | 0.0098 | 4.5074 | 39.93 | 44.05 |
| 35 | 2.5000 | 0.0033 | 0.0163 | 0.8966 | 0.0146 | 4.4463 | 35.42 | 39.51 |
| 40 | 2.5000 | 0.0042 | 0.0209 | 0.8820 | 0.0184 | 4.3639 | 30.97 | 35.12 |
| 45 | 2.5000 | 0.0055 | 0.0273 | 0.8636 | 0.0236 | 4.2588 | 26.61 | 30.81 |
| 50 | 2.5000 | 0.0083 | 0.0406 | 0.8400 | 0.0341 | 4.1146 | 22.35 | 26.61 |
| 55 | 2.5000 | 0.0111 | 0.0542 | 0.8059 | 0.0436 | 3.9202 | 18.24 | 22.63 |
| 60 | 2.5000 | 0.0231 | 0.1090 | 0.7622 | 0.0831 | 3.6035 | 14.32 | 18.78 |
| 65 | 2.5000 | 0.0214 | 0.1015 | 0.6792 | 0.0689 | 3.2235 | 10.71 | 15.77 |
| 70 | 2.5000 | 0.0338 | 0.1558 | 0.6103 | 0.0951 | 2.8136 | 7.49 | 12.27 |
| 75 | 2.5000 | 0.0485 | 0.2164 | 0.5152 | 0.1115 | 2.2971 | 4.68 | 9.08 |
| 80 | 2.5000 | 0.1137 | 0.4426 | 0.4037 | 0.1787 | 1.5717 | 2.38 | 5.89 |
| 85 | 3.5868 | 0.2788 | 1.0000 | 0.2250 | 0.2250 | 0.8070 | 0.81 | 3.59 |
In your problem set for this week, you’ll compare the results of this graduation-based life table to one Using rules of thumb below.
3.2.3 Borrowing average person-years lived (\({}_{n}a_x\)) values from another population
- If your \({}_{n}m_x\) curve is similar to another population, perhaps the \({}_{n}a_x\) values are similar, too
- The question is, how to find a similar enough model life table?
- You’ll learn a lot more about this in CS&SS/SOC/STAT 563 (Statistical Demography & Data Science).
3.2.4 Using rules of thumb
By “rules of thumb,” PHG mean “simple parametric assumptions”
Assume people die on average half-way through interval (\({}_{n}a_x = n/2\))
PHG introduce this at the beginning of the period life table section, but I think it makes more sense to put it here. Under this assumption:
\[ {}_{n}q_x = \frac{ n \cdot {}_{n}{m_x} }{ 1 + \frac{1}{2} \cdot n \cdot {}_{n}m_x } = \frac{2n \cdot {}_{n}m_x}{2 + n \cdot {}_{n}m_x} \]
Under what conditions is this assumption exactly true? Tap for answer
- Linear growth or decline in death count during the period (remember the midpoint theorem from week 1)
- Deaths distributed symmetrically about the mid-period
- The shorter the period and the more linear the death curve, and the more reasonable this assumption
How does this assumption perform if mortality rate is decreasing very rapidly? Tap for answer
Over-estimate \({}_{n}a_x\) because most deaths would occur early in the interval (see section on The very young ages)How would this assumption perform if death count were increasing exponentally over the period? Tap for answer
Under-estimate \({}_{n}a_x\)When does this assumption lead to a \({}_{n}q_x\) estimate that makes no sense? Tap for answer
A value \({}_{}q_x > 1\) makes no sense. Yet that’s what will happen if:
\[\begin{align} {}_{n}q_x &= \frac{2n \cdot {}_{n}m_x}{2 + n \cdot {}_{n}m_x} > 1 \rightarrow n/2 > 1/{{}_{n}m_x} \rightarrow n/2 > {}_{n}L_x/{}_{n}d_x \\ &= \textsf{Time to mid-period} > \textsf{Expected time to death} \end{align}\]
In words, don’t assume that the expected time to death from age \(x\) is the mid-period if age-specific mortality tells you the expected time to death is in fact before the mid-period!
Look out for this issue in:
- High-mortality populations
- High-mortality age groups (e.g., very old ages)
- High-mortality age groups in high-mortality populations
Assume constant death rate \({}_{n}m_x\) throughout the interval
Under this assumption:
\[\begin{equation} {}_{n}q_x = 1 - e^{-n \cdot {}_{n}m_x} \tag{3.2} \end{equation}\]
Equating the right hand side in the equation above to that of (3.1) reveals that:
\[ {}_{n}a_x = n + \frac{1}{{}_{n}m_x} - \frac{n}{1 - e^{-n \cdot {}_{n}m_x}} < n/2 \]
The final inequality means that assuming constant death rate further assumes that deaths are concentrated near the beginning of age intervals.
Life table results are fairly insensitive to error in choice of \({}_{n}a_x\)
The re-written \({}_{n}m_x \rightarrow {}_{n}q_x\) conversion equation reveals that \({}_{n}a_x\) is multiplied by \({}_{n}q_x\) before entering the formula
\[ {}_{n}q_x = \frac{ n \cdot {}_{n}m_x }{ 1 + n \cdot {}_{n}m_x - \color{red}{{}_{n}a_x \cdot {}_{n}m_x} } \]
- Global death rate \(\approx\) 0.012
- So an error of 2 years in one \({}_{n}a_x\) means \({}_{n}q_x\) off by < 1%
- i.e., a small number < 1 is multiplied by another small number < 1 to yield an even smaller number
- So your choice among rules of thumb, etc., matters less than you think it does
- But still check the robustness of your results as much as you can
3.3 The very young ages
Life table results are very sensitive to procedures for very young age groups, where mortality rates rapidly decline and the \({}_{n}a_x = n/2\) assumption breaks down.
Problem: In low mortality population, most children who die do so very early in life (especially among infants), so it’s possible that \({}_{n}a_{x} \ll n/2\)
Potential solution: Use output from statistical models of relationships between \({}_{n}a_x\) and \({}_{1}m_0\) in young age groups
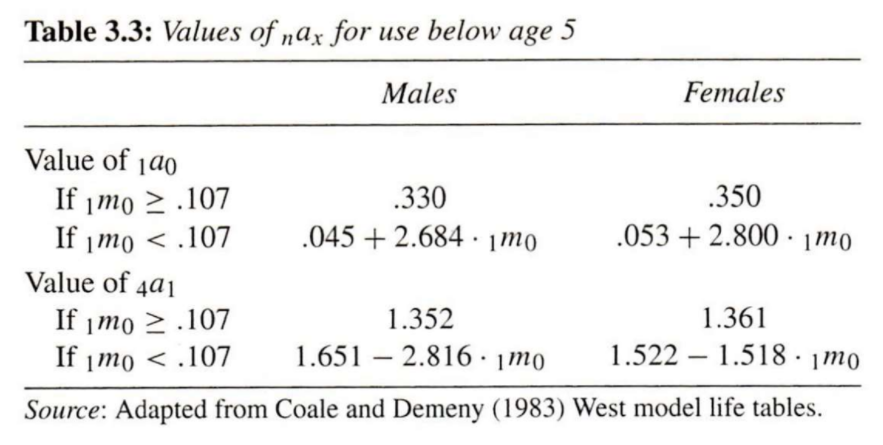
PHG Table 3.3
To do this in R, you could some functions. For example (yes, this code could be less repetitive):
ax_young <- function(m0, # mortality rate from ages 0 to 1
a, b, c) { # parameters of the model
ifelse(m0 >= 0.107, a, b + c * m0)
}
# For youngest age group 1a0
a0_male <- function(m0) ax_young(m0, 0.330, 0.045, 2.684)
a0_female <- function(m0) ax_young(m0, 0.350, 0.053, 2.800)
# For a four-year age interval between 1 and 5 (i.e., 4a1)
a1_male <- function(m0) ax_young(m0, 1.352, 1.651, -2.816)
a1_female <- function(m0) ax_young(m0, 1.361, 1.522, -1.518)
# Sanity check using Australian data from PHG Box 3.1
aus_m0 <- 0.008743
a0_male(aus_m0)## [1] 0.06846621
a1_male(aus_m0)## [1] 1.62638In reality, there are well-tested software packages to perform such tasks automatically (e.g., demogR)
What are potential pitfalls of using statistical models trained from historical data to model \({}_{1}a_0\) and \({}_{1}a_1\)? Tap for answer
- Depending on the data used to train the model, it may not generalize to contemporary or future observations
- The usual bias-variance trade-off issues with building predictive models
- Assume incorrect functional form
The bath tub shape of many single decrement processes
This guidance seems highly specific to the study of mortality, but it isn’t. We see it in settings ranging from mechanical part failure to employee attrition.
The bath tub shape is theorized to be the sum of three processes, illustrated below:

From Wikimedia: https://commons.wikimedia.org/wiki/File:Bathtub_curve.svg
{kind=link}
3.4 The open-ended age interval
In a cohort life table, you follow everyone until they die.
But in a period life table, you don’t know the maximal age at death.
So how do you fill in \({}_{\infty}L_x\) and \(T_x\) in this “open-ended” age interval?
KEY CONCEPT
For the oldest age group starting with age \(x = x^*\), age interval length \(n = \infty\). This age group is called the open-ended interval.
Ideally, choose \(x^*\) so that a very small fraction of individuals survive to it
Because \(n = \infty\):
- \({}_{\infty}q_{x^*} = 1\) (“In the end, we’re all dead.”)
- \({}_{\infty}p_{x^*} = 1 - {}_{\infty}q_{x^*}= 0\) (In the end, none of us lives.)
- \({}_{\infty}d_{x^*} = l_{x^*}\) (Good to know since we can’t observe who dies after \(\infty\) years)
Recall that:
\[ {}_{\infty}m_{x^*} = \frac{ {}_{\infty}d_{x^*} }{ {}_{\infty}L_{x^*} } \rightarrow {}_{\infty}L_{x^*} = \frac{ {}_{\infty}d_{x^*} }{ {}_{\infty}m_{x^*} } \]
Plugging in \({}_{\infty}d_{x^*} = l_{x^*}\):
\[ {}_{\infty}L_{x^*} = \frac{l_{x^*}}{{}_{\infty}m_{x^*}} \]
Both numerator and denominator are things we can observe within a period.
So what’s \(T_{x^*}\) for the oldest age group \(x^*\)?
\(T_{x^*} = {}_{\infty}L_{x^*}\) because there are no further age groups to curtail person-years lived above age \(x^*\)3.5 Review of the steps for period life table construction
Let’s walk through the steps of life table construction using the tidyverse in R and data on age-specific mortality in Ukraine in 2013. In this course, you can use whatever package you want to build life tables except for packages that automatically calculate them for you.
Here’s the data (changing the original Age column in the Human Mortality Database to x to match our notation):
| x | mx |
|---|---|
| 0 | 0.007944 |
| 1 | 0.000585 |
| 2 | 0.000392 |
| 3 | 0.000243 |
| 4 | 0.000204 |
| 5 | 0.000212 |
\(\vdots\)
| 105 | 0.483072 |
| 106 | 0.490520 |
| 107 | 0.512695 |
| 108 | 0.583352 |
| 109 | 0.654123 |
| 110 | 1.368043 |
Step 1: Adopt a set of \({}_{n}a_x\) values
For simplicity, we’ll adopt the mid-period assumption:
\[{}_{n}a_x = n/2\]
In practice, you should not do this for The very young ages
ukr_plt_1x1_2013 <- ukr_mx_1x1_2013 %>%
dplyr::mutate(nx = dplyr::lead(x) - x, # Define length of period
ax = nx / 2) # Define assumed person-years among the deadIf instead we assumed constant death rate \({}_{n}m_x\) throughout the interval, we could have skipped this step because:
- Recall from Equation (3.2) that we don’t need \({}_{n}a_x\) to compute \({}_{n}q_x\) under constant mortality \({}_{n}m_x\)
- And \(l_x\) is a function of \({}_{n}p_x = 1 - {}_{n}q_x\)
Step 3: Compute \({}_{n}p_x = 1 - {}_{n}q_x\)
ukr_plt_1x1_2013 <- ukr_plt_1x1_2013 %>%
dplyr::mutate(px = 1 - qx)Step 4: Choose a radix \(l_0\)
By setting an arbitrary starting population size, you can calculate the remaining columns from what you’ve computed so far. It doesn’t really matter what the radix is, so long as it is positive. Many sources use \(l_0 = 100,000\)
l0 <- 100000Step 5: Compute the remaining \(l_x\) values from \({}_{n}p_x\) values
\[ l_1 = l_0 \times {}_{1}p_0 \\ l_2 = l_1 \times {}_{2}p_1 \\ \vdots \] In code, this process requires iteration:
Step 6: Derive \({}_{n}d_x\) as \(l_{x+n} - l_{x}\) or \(l_x \cdot {}_{n}q_x\)
You don’t need to fill in the open-ended interval \({}_{\infty}d_{x^*} = l_{x^*}\) because you’ve already imputed \({}_{\infty}q_{x^*} = 1\)
ukr_plt_1x1_2013 <- ukr_plt_1x1_2013 %>%
dplyr::mutate(dx = lx * qx)Step 7: Derive person-years lived between ages \(x\) and \(x+n\)
Recall that:
\[{}_{n}L_x = n \cdot l_{x+n} + {}_{n}a_x \cdot {}_{n}d_x\]
Step 8: Derive \(T_x = \sum_{a=1}^\infty {}_{n}L_x\)
This code should look familiar from our cohort life table construction:
ukr_plt_1x1_2013 <- ukr_plt_1x1_2013 %>%
dplyr::mutate(
Tx = rev(Lx) %>% # Reverse person-years column so sum back to x = 0
dplyr::coalesce(0) %>% # Replace the missing value in the open interval
cumsum() %>% # so can take the cumulative sum of person-years
rev() # Reverse the cumulative sum back in age order
)Note there is no need to fill in a missing value for the open age interval because we’ve already imputed Lx as lx/mx, and it was the first value in the cumulative sum computed above.
Step 9: Derive life expectancy \(e^o_x\) at age \(x\)
Recall that \(e^o_x = T_x/l_x\)
ukr_plt_1x1_2013 <- ukr_plt_1x1_2013 %>%
dplyr::mutate(ex = Tx/lx)Let’s take a look at our constructed period life table for Ukraine 2013.
And do a quick sanity check using the Human Mortality Database’s (much more sophisticated) pre-made life table for Ukraine 2013:
Visualizing life table columns
We’ve already seen what a mortality rate curve looks like. Let’s see other columns.
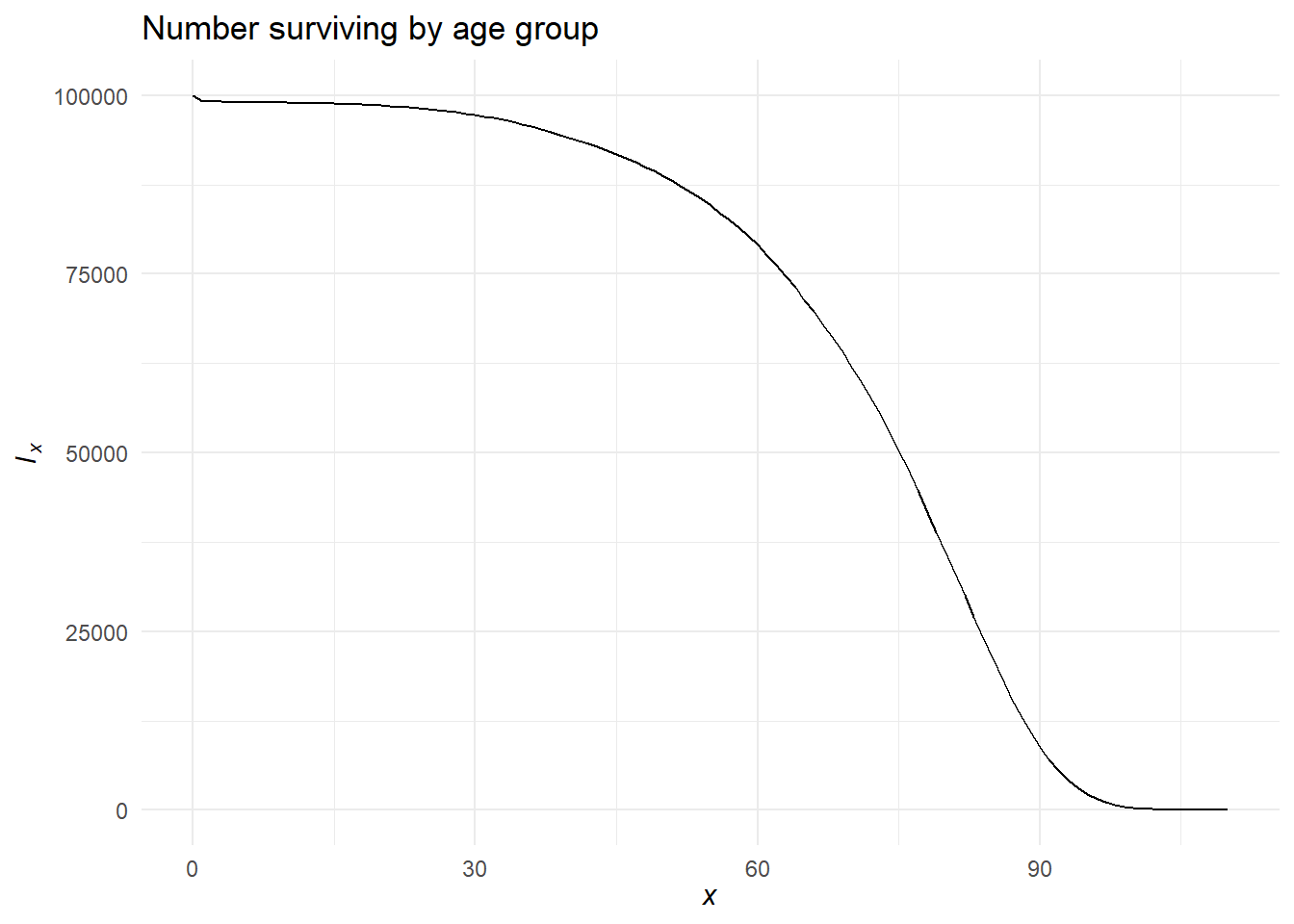
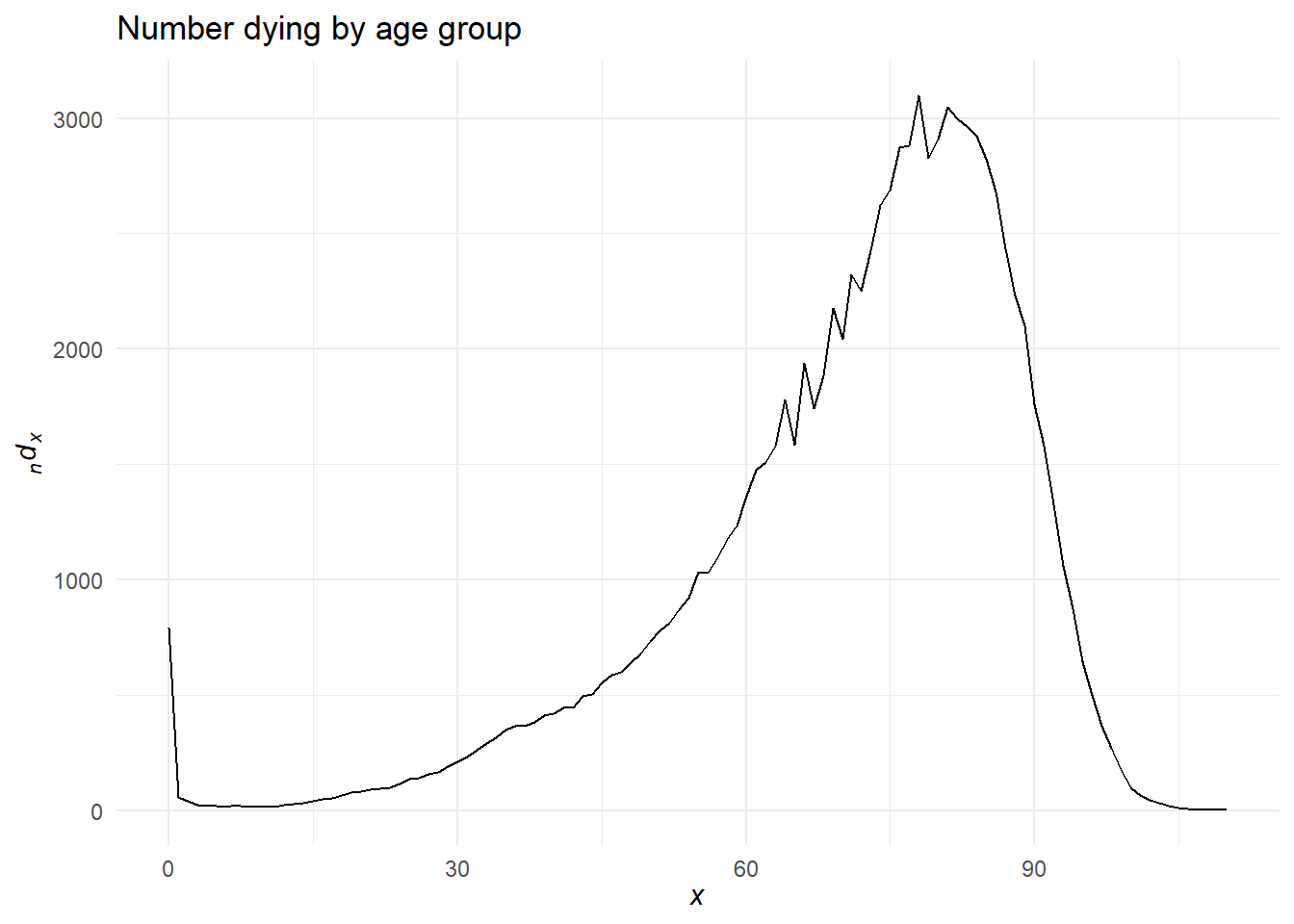
And let’s try an interactive look at \(l_x\) and \({}_{n}d_x\) for Italy made by Eddie Hunsinger: https://shiny.demog.berkeley.edu/eddieh/lx_ndx_Italy/
3.6 Interpreting the life table
You can combine column values at different ages in meaningful ways:
-
\(l_y / l_x = {}_{y-x}p_x\): Probability of surviving from age \(x\) to age \(y\)
- Special case: \(p(x) = l_x/l_0\) is probability of surviving from birth to age \(x\) (In survival analysis, this is known as the survivor curve)
-
\(1 - l_y/l_x = {}_{y-x}q_x\) Probability of dying between ages \(x\) and \(y\)
- Special case: \(1 - p(x) = 1 - l_x/l_0 = {}_{x}d_0/l_0\) is the cumulative probability of dying before reaching age \(x\) (In survival analysis, this is known as the cumulative incidence function or cumulative density function)
-
\(\left(l_y - l_z\right)/l_x\): Probability that one who reaches age \(x\) dies between ages \(z\) and \(y\)
- Special case: \(\left(l_y - l_x\right)/l_0\) Probability someone born dies between ages \(x\) and \(y\)
- \(\left(T_y - T_z\right)/l_x\): Expected person years lived between ages \(y\) and \(z\) by someone who reaches age \(x\)
3.7 The life table conceived as a stationary population
KEY CONCEPT
A stationary population meets the following demographic conditions:
- Age-specific death rates are constant over time
- Constant annual flow of births
- Age-specific net migration rates are zero
Once a single cohort has lived through all age groups, these conditions result in:
- Constant age structure
- Constant population size by age group
- Thus constant population size
Interpreting life table columns in a stationary population:
- \(l_x = l_0 \cdot {}_{x}p_0\): Number of persons who reach age \(x\) in any calendar year
- \({}_{n}L_x\): Number of persons alive at any point in time between ages \(x\) and \(x+n\)
- \(T_x\): Number of persons alive at any point in time above age \(x\), so that \(T_0\) is total population size
- \({}_{n}d_x\): Annual number of deaths between ages \(x\) and \(x+n\)
- \(e_0^o\): Mean age at death for persons dying in any particular year33
Other useful results specific to a stationary population:
- \(CBR = CDR = 1/e^o_0\)
- Death rate above age \(x\): \({}_{\infty}M_{x} = 1/e_x^o\)
- Age structure \({}_{n}C_x = {}_{n}L_x/T_0 \approx \frac{l_{x+n/2}}{l_0} \cdot n \cdot CBR\)
Why are these results useful:
- You can use them to calculate missing demographic statistics from those you have
- They’re often approximately correct even in a non-stationary population, at least one that grows slowly, or is not observed for too long
- But be careful, especially with the assumption that \(e_0^o\) is mean age at death
Wait… why is stationary population age structure and size constant?
- Below is Table 3.5 from PHG pg. 55
- This table tracks a population within constant 1,000 births per day
- Tracking age by days to understand person-years lived from ages 0 to 1 years
- Let’s walk through what’s happening
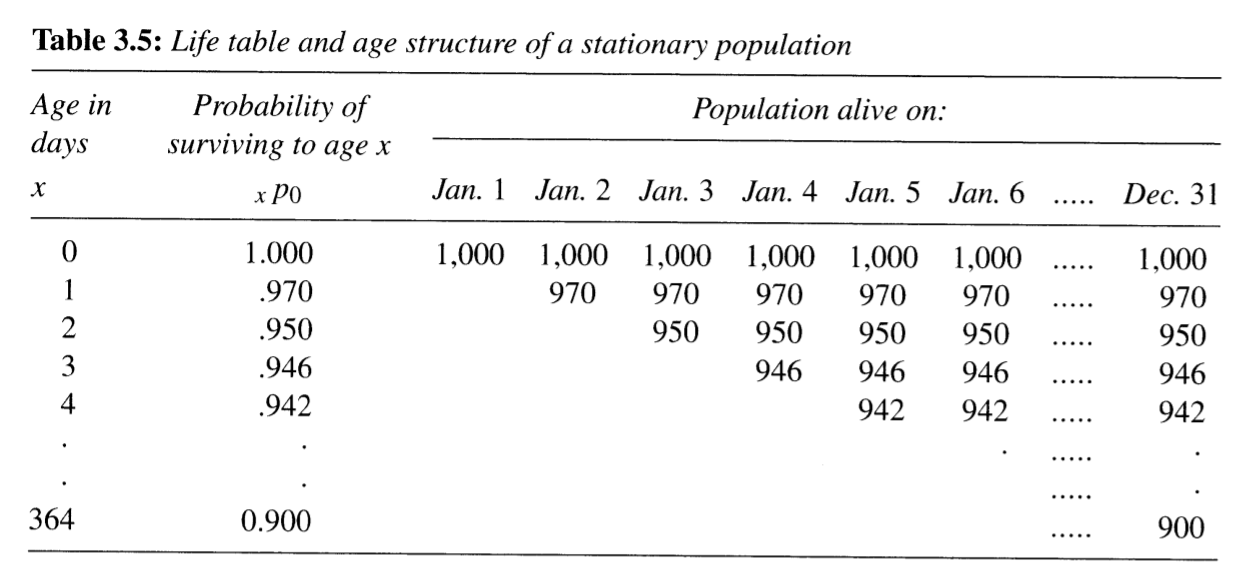
Okay, so:
- Number of people by exact age in days is constant
- So number of people aged 0 to 1 years at any point in time must be:
\[{}_{1}N_0 = 1000 + 970 + 950 + 946 + 942 + \cdots + 900\]
- For each daily cohort, one day in a year represents 1/365 person-years (duh):
- For Jan 1 daily cohort, 1000 people lived 1/365 person-years on Jan 1
- The next day, 970 people in the same cohort lived 1/365 person-years
- And so on…
- Remember, the number of people at age \(x\) in days is constant!
- So the number of person-years lived by those aged 0 to 1 years must be:
\[ \require{cancel} \begin{align} {}_{1}L_0 &= 365 \times [1000/365 + 970/365 + 950/365 + \cdots + 900/365] \\ &= \bcancel{365} \times \frac{1}{\bcancel{365}} \times [1000 + 970 + 950 + \cdots + 900] \\ &= [1000 + 970 + 950 + \cdots + 900] \\ &= {}_{1}N_0 \end{align} \]
This same logic works for every age group (except they have a different starting population size defined by \(l_x\))
3.8 Mortality as a continuous process
KEY CONCEPT
Force of mortality: The mortality rate measured over an infinitesimally small amount of time.
\[\begin{equation} \mu(x) = \lim_{n \rightarrow 0}\left[\frac{l(x) - l(x+n)}{n \cdot l(x)}\right] = \frac{-d\text{ln(l(x))}}{dx} \tag{3.3} \end{equation}\]
Other names for this concept in survival analysis, reliability theory, and event history analysis:
- failure rate
- hazard function
From the force of mortality, we find that:
\[ l(z) = l(y)e^{-\int_y^z \mu(x)dx} \]
Recall the discrete-time equation \({}_{x+n}p_x = l_{x+n}/l_x\)34. From the above, we see the continuous case:
\[\begin{equation} l(z)/l(y) = {}_{y-x}p_z = e^{-\int_y^z \mu(x)dx} \tag{3.4} \end{equation}\]
Important finding here: The proportionate change in cohort size between two ages is completely a function of the sum of the force of mortality between those two ages. Look familiar35?
3.9 Life table construction revisited
What does our life table construction assume about cohort age-specific rates \({}_{n}m_x\)? Tap for answer
That they are the same as as period age-specific rates \({}_{n}M_x\)In this section, PHG show conditions when this assumption is incorrect.
Recall \({}_{n}m_x = {}_{n}d_x / {}_{n}L_x\)
A continuous formula for number of deaths between ages \(x\) and \(x+n\):
\[{}_{n}d_x = \int_x^{x+n} l(a)\mu(a)da\]
And for person-years lived between \(x\) and \(x+n\):
\[{}_{n}L_x = \int_x^{x+n} l(a)da\]
So the cohort age-specific mortality rate between \(x\) and \(x+n\):
\[
{}_{n}m_x
= \frac{{}_{n}d_x}{{}_{n}L_x}
= \frac{
\int_x^{x+n} \color{darkorange}{l(a)}\mu(a)da
}{
\int_x^{x+n} \color{darkorange}{l(a)}da
}
\]
- Right-hand side is a weighted average of the force of mortality
- Weights are the number of survivors \(\color{darkorange}{l(a)}\) in the cohort
Yet the period age-specific mortality rate is:
\[\begin{equation} {}_{n}M_x = \frac{ \int_x^{x+n} \color{dodgerblue}{N(a)}\mu(a)da }{ \int_x^{x+n} \color{dodgerblue}{N(a)}da } = \int_x^{x+n} c(a)\mu(a)da \tag{3.5} \end{equation}\]
- Here, weights are period age counts \(\color{dodgerblue}{N(a)}\) NOT cohort age counts \(\color{darkorange}{l(a)}\)
- Thus it’s possible for \({}_{n}m_x \neq {}_{n}M_x\)
Only two conditions when we’re certain \({}_{n}m_x = {}_{n}M_x\)
Condition 1: Force of mortality \(\mu(a)\) is constant \(\color{purple}{\mu^*}\) between ages \(x\) and \(x+n\), thus:
\[ \require{cancel} {}_{n}M_x|_{\mu(a) = \mu^*} = \color{purple}{\mu^*} \cdot \frac{ \bcancel{\int_x^{x+n} \color{dodgerblue}{N(a)}da} }{ \bcancel{\int_x^{x+n} \color{dodgerblue}{N(a)}da} } = \color{purple}{\mu^*} = \color{purple}{\mu^*} \cdot \frac{ \bcancel{\int_x^{x+n} \color{darkorange}{l(a)}da} }{ \bcancel{\int_x^{x+n} \color{darkorange}{l(a)}da} } = {}_{n}m_x|_{\mu(a) = \mu^*} \]
Plugging \({}_{n}M_x = \mu^*\) into the continuous survival probability \({}_{n}p_x\) from (3.4):
\[{}_{n}p_x = \frac{l_{x+n}}{l_x} = e^{-{}_{n}M_x \cdot n}\]
This should look familiar as the complement of the \({}_{n}m_x \rightarrow {}_{n}q_x\) conversion that assumed constant mortality.
Condition 2: \(N(a)\) constantly proportional to \(l(a)\) throughout interval
Suppose \(N(a) = k \cdot l(a)\) for all \(a\). Then:
\[ \require{cancel} \begin{align} {}_{n}M_x &= \frac{ \int_x^{x+n} k \cdot \color{darkorange}{l(a)}\mu(a)da }{ \int_x^{x+n} k \cdot \color{darkorange}{l(a)}da } = \frac{\bcancel{k}}{\bcancel{k}} \cdot \frac{ \int_x^{x+n} \color{darkorange}{l(a)}\mu(a)da }{ \int_x^{x+n} \color{darkorange}{l(a)}da } \\ &= \frac{ \int_x^{x+n} \color{darkorange}{l(a)}\mu(a)da }{ \int_x^{x+n} \color{darkorange}{l(a)}da } = {}_{n}m_x \end{align} \]
This constant proportionality occurs in stationary population… or by chance
3.10 Decomposing a difference in life expectancies
The difference between two life expectancies at birth \(e^o_0(2) - e_0^o(1)\) can be decomposed into separate contributions \({}_{n}\Delta_x\) from each age group:
\[ e^o_0(2) - e_0^o(1) = \sum_0^\infty {}_{n}\Delta_x \]
Below is the life-expectancy difference decomposition for all age groups comparing U.S. women 1995 vs. 193536
An age-specific difference contribution \({}_{n}\Delta_x\) can itself be decomposed into two main components:
\[{}_{n}\Delta_x = \frac{l_x^1}{l_0^1} \cdot \left(\frac{{}_{n}L_x^2}{l_x^2} - \frac{{}_{n}L_x^1}{l_x^1}\right) + \frac{T^2_{x+n}}{l_0^1} \cdot \left(\frac{l_x^1}{l_x^2} - \frac{l_{x+n}^1}{l_{x+n}^2}\right)\] Above, superscripts indicate the associated life expectancy in the difference, e.g., \(l^1_x\) is number of survivors to age \(x\) associated with \(e_0^o(1)\).
- \(\frac{l_x^1}{l_0^1} \cdot \left(\frac{{}_{n}L_x^2}{l_x^2} - \frac{{}_{n}L_x^1}{l_x^1}\right)\) is the direct effect of the change in mortality rates between ages \(x\) and \(x+n\) on life expectancy at birth.
- \(\frac{T^2_{x+n}}{l_0^1} \cdot \left(\frac{l_x^1}{l_x^2} - \frac{l_{x+n}^1}{l_{x+n}^2}\right)\) are the indirect effect and interaction effects resulting from future person-years to be added (or subtracted) because additional (or fewer) survivors at age \(x+n\) are exposed to new mortality conditions.
- The open-ended interval has no indirect effects because there are no future age groups to observe, thus \({}_{\infty}\Delta_x = \frac{l_x^1}{l_0^1} \cdot \left(\frac{T_x^2}{l_x^2} - \frac{T_x^1}{l_x^1}\right)\)
- These results could be extended to any life expectancy \(e_a^o\) by replace all \(l_0\) with \(l_a\) and estimating \({}_{n}\Delta_x\) for \(x \geq a\)
3.11 Adaptation of the life table for studying other single decrement processes
In some processes, there are multiple ways to exit:
- Multiple ways to die
- Multiple reasons for leaving a company
- Etc.
These are called multiple decrement processes and we’ll cover them next week.
PHG highlight three cases where a single decrement process can shed light on what is in fact a multiple decrement process:
- Collapse multiple decrement processes into one process of substantive interest
- Study one of the decrements of interest (e.g., marriage) by asking those who didn’t succumb to another decrement (e.g., death)
- Perform a “thought experiment” (aka, conceive of an intervention) that removes one or more decrement processes until there is only one remaining
Let’s discuss:
- Applications of each of these scenarios
- Caveats to each of these scenarios